The point of this guide is for the casual developer to get a cursory understanding of artificial intelligence concepts necessary to begin making applications that use various frameworks, libraries, or source code. Having straddled both the software engineering and academic research oriented sides of AI development, I understand how nuanced both approaches can be, especially when the mobile constraints of memory and performance are added to the mix.
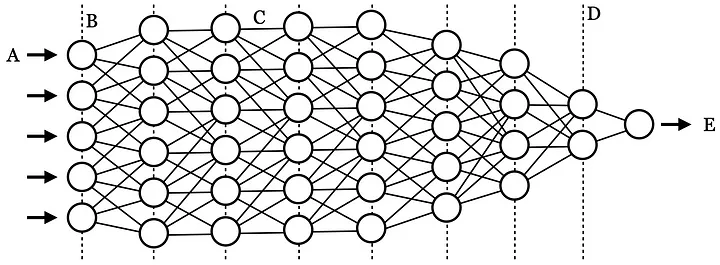
Figure 1. Illustration of a neural network
The following are concepts should help you understand tutorials or documentation about SDKs and APIs related to AI a little better, without requiring any additional background reading.
The difference between AI, Deep Learning, and Machine Learning
A whole article can be written about the nuances between these concepts. However, put simply, AI is a general term used to describe human-like problem solving done by computers, whereas Deep Learning and Machine Learning refer to specific implementations used to perform AI. Specifically, Machine Learning typically uses fewer unique features to build a statistical understanding of what it sees, whereas Deep Learning uses many features.
For example, Figure 2 shows how group A and group B can be separated by leaf length and height (over 2 dimensions, x and y) via a margin, and an unknown plant can be classified as being in group A or B by where it falls on either side of this margin.
Deep Learning, on the other hand, needs a lot of unique features, and more closely resembles the way a human brain learns and understands. For example, Figure 1 shows how the many features found in a photograph are input in A, along many different layers in B, until it is output as E.
Machine Learning can be used as a general term covering more specific Deep Learning algorithms, but is increasingly used to describe more traditional methods like SVM, kNN, and other low dimensional learning methods.
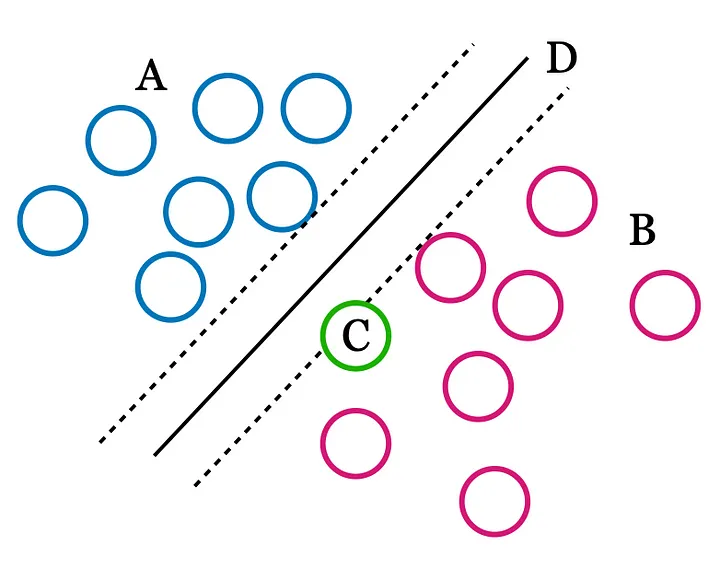
Figure 2. Illustration of Support Vector Machines (SVM) margin
What are features
In Machine Learning, features are the many measured attributes of a thing being learned e.g., the leaf colour and size of a plant seen as the x and y axis of points in Figure 2, or the many input features seen as A in Figure 1. There could be many features or just a few, but as features increase, prediction with Machine Learning becomes more difficult. One way Deep Learning addresses this limitation is through Convolutional Neural Networks, where something like an image is layered into its various edges, colours, and other graphical perturbations. As a CNN observes and tracks these many different perturbations it learns the differences and similarities between images with the same names. This is distinctly different to a Machine Learning algorithm like Support Vector Machine seen in Figure 2, where smaller feature sets are statistically grouped into clusters separated by margin D. In Figure 2, the vectors touching hyperplane D are the support vectors defining the margin that classifies points on either side of it as group A or B.
Difference between Class and Label
Let’s say you have a list of plant data with different stem lengths, leaf colours, and heights. Each plant will have a name associated with it, which is typically referred to as its label, or class name. Now let’s say you measure a plant in the wild, and you want to predict what it is, you can plug in the stem length, leaf colour, and height of it to get a class name back as a prediction. This is known as classification. However, what if none of the plants in the list have labels, and you want to see if your mystery plant is similar to a cluster of unlabelled mystery plants in your data set? In this case, you will get an numbered cluster id back as a label, but it is not a class because there is no classification taking place. The difference between class and label is not always enforced but this is a nuanced difference worth understanding as we tackle the next concept.
Supervised and Unsupervised learning
In the previous example, we saw how we can assign a name, as a label, to our data set of plant stem lengths, leaf colours, and heights. When training our Machine Learning algorithm, it can take a new unknown stem length, leaf colour, and height to predict or classify it. However, what if we have the data but no labels? For example, in Figure 2, could be automatically find the margin? Could we ask the algorithm to predict how many different types of plants we have in our data set? Yes, this is called unsupervised learning. In this scenario, the algorithm returns a unique id belonging to each cluster sharing the most attributes in common with each other. Parameters in the algorithm can make clusters more inclusive or exclusive, and sometimes a lot of tweaking and interpretation is required to prevent too many or too few unsupervised labels.
What is a Tensor
You have probably heard of Tensorflow, by Google. A tensor is a mathematical structure used to describe an input used in a calculation. Other structures you may have heard of include scalars, matrices, and vectors. Tensors are used “under the hood” in a lot of Deep Learning algorithms and aren’t exclusively used in AI.
Transfer Learning
Basically, transfer learning takes a previously created model and adds new training and labels to it. But this is more complicated that it sounds. A typical Deep Learning model, like the one seen in Figure 1, contains many layers (D), and some of these layers need to be removed, appended, and re-trained when transfer learning. Often, engineers will pick a trained model used to recognise general objects with general labels, and then use transfer learning to train the model to recognise specific things, e.g., brain tumours.
Class models and training
By now, you understand what classes and features are, which are both necessary to understand models. A model is a repository of features linked to class names used as a reference when a Deep Learning algorithm makes a prediction. Training is the process of feeding inputs, e.g., images, into an AI algorithm so it can separate unique distinguishing features into bins belonging to specific classes. Models are constructed during training, for example, an image of a cat that’s used as an input to a Deep Learning algorithm is broken down layer by layer, with features of the image saved into the overall model used to separate features of the cat from dogs, lighthouses, cars, and other classes in the model.
Convolutions
A convolution describes both how and what is produced when two or more actions produce a result. For example, if you take a shape and both stretch and rotate it, the convolution will be both the stretched and rotated image, and the mathematical geometry that describes its transformation. In this example, we could use a matrix to describe the affine transformation, but we could also use tensors to describe convolutions between layers, such as the D dotted lines in Figure 2 illustrating a neural network. In fact, this is a basic description of how Convolutional Neural Networks (CNN) process inputs during training.
Activation Functions
In between the convolution layers, i.e., dotted lines D in Figure 2, neural network are weights and biases, as seen in C, that change the influence of one layer to another. These are called activation functions, and are used to tune how the layers handoff their transformations to one another. These activation functions can mute, slope, turn on or off, or slightly change input features between layers in order to amplify or attenuate. Sometimes this term is used interchangeably with the term transformation function, though usually a transformation function includes both the activation and output function. The key thing to understand here is that activation functions define the output of the input through some kind of transformation filter.
I’ll be adding to this list as I get feedback from friends, co-workers, and others who have questions about AI concepts. These definitions would definitely not be adequate as a scholarly description used in a classroom setting. But hopefully, they will provide you with a general understanding of terms and concepts thrown around in documentation accompanying AI frameworks, libraries, and source code.


